ASK THE EXPERT: Bayesian Theorem and using it to perform Sentiment Analysis
By Jamie Maguire

Jamie Maguire is a Microsoft MVP, software architect, and a community leader in his roles at Code Club and STEM Learning UK. In the following blog post, he’s outlined how you can use Bayesian Theory to perform sentiment analysis, while we explore whether Microsoft Azure can do this for you out of the box…
Since the inception of the world wide web users have taken to online websites and services to discuss and share things that are important to them.
For at least the last 10 years, platforms such as Facebook, Instagram Twitter and LinkedIn have grown in popularity and more than ever, users take to these platforms to express how they feel about the current news story of the day, or to rant or rave about a product, brand or service.
It’s possible to query and extract datasets from these social media networks platforms using their respective developer APIs. This can contain comments being left, user information, location data and more.
Valuable insights can be surfaced from user comments, one of which is the underlying emotion being expressed. Is it positive? Great news if you just launched a new product! Or, is it negative? Maybe you have a potential digital PR disaster about to kick-off!
Identifying this is known as sentiment analysis and is what we’ll explore in this blog.
Specifically, we’ll look at Bayesian Theorem and how it can used to perform sentiment analysis.
Are Microsoft pros using Microsoft Azure for sentiment analysis?
Our annual, independent Microsoft Azure report explores salaries, culture, and products in the Azure ecosystem – there’s no better way to learn how businesses are utilizing this technology.
The Bayesian Rule
This is a technique that’s used to arrive at predictions in light of relevant evidence. It is also known as conditional probability or inverse probability. The theorem that was discovered by an English Presbyterian and mathematician called Thomas Bayes and published posthumously in 1763.
The Bayesian Rule itself is written like this (where A and B are two events):
p(A|B) = p(B|A) p(A) / p(B).
Let’s break this down first for clarity:
p(A|B)
The probability of A given B. This basically means the probability of finding observation A, given that some part of evidence B is there. This is what we want to find out.
p(B|A)
This is the probability of the evidence turning up (given that A has already happened).
p(A)
This is the probability of the outcome occurring, without the knowledge of the new evidence.
p(B)
This is the probability of the evidence arising, without regard to the outcome.
The rule is effectively a way of looking at the conditional probabilities of an event using a given set of mathematical probabilities.
An example of Bayesian Theorem in action
We’ve just introduced the Bayesian Rule so now’s a good time to add some numbers to the rule which will make more sense!
A common use case for Bayesian Theorem is in the creation of classifiers that can detect whether email is valid, or if it’s a spam email.
Imagine you have software that looks for patterns in the subject line and body of emails and are looking to build a classifier that can identify if email is spam or is a valid email.
After some analysis, users report that:
- the word “free” appears in 30% of emails marked as spam
- 5% of non-spam email includes the word “free”
- 50% of all emails received by the user is spam
You need to figure out the probability that an email is spam if the word “free” appears in it.
Data
First, let’s map the data we’ve outlined to the respective parts of the theorem:
- P (“free” | Spam) = 0.30
- P (“free” | Non-Spam) = 0.005
- P (Spam) = 0.50 => P (Non-Spam) = 0.50
- P (Spam | “free”) = <this is what we want to figure out>
Applying Bayesian Theorem
Next, we plug these values into the theorem:
- P (Spam | “free”) = P (Spam) * P (“free” | Spam) / P (“free”)
- P (Spam | “free”) = 0.50 * 0.30 / (0.50 * 0.30 + 0.50 * 0.005)
Output
Finally, after crunching the above we perform the final calculation:
P (Spam | “free”) = 0.983607
Or, in plain English and based on existing data, there is a 98% chance that emails containing the word “free” are spam type emails!
Sentiment analysis with Bayesian Theorem
We’ve just looked at Bayesian Theorem and an example of how it can be used to identify if incoming mail should be classified as spam email or not, but how does can this same approach be used to perform sentiment analysis?
At a high-level, sentiment analysis is a text classification problem where you’re looking to categorize text into either positive or negative categories.
Training data
One of the first things you need to do is collect examples of positive and negative phrases. For example, if you were looking to classify the content of Tweets, you should build a corpus which contains examples of tweets that express these two types of emotion.
After you have a sufficiently sized dataset, the next thing you need to do is to perform a data cleansing exercise. This is also known as pre-processing.
Data cleansing
This involves a few steps and what follows is by no means exhaustive. At a high level, it’s beneficial to perform the following tasks to get your data in ship-shape:
- Unwanted characters – here you remove (or replace) all tags or text that aren’t generally part of the language you’re processing. For example, a website URL or social media username can be swapped out for constant values URL and USR. As you move onto later stages of the data cleansing exercise, these constant values will make it easier to process your text and ultimately improve the speed.
- Attached Words – On social media, its common for words to be joined with no spaces in between, hashtags are good examples of this, e.g. #MondayMotivation. There can be value in splitting these into the discrete words. This can be done by identifying capital letters, doing so will give you additional information that can help your classification efforts.
- Casing – Next, depending on how sensitive you want your sentiment analysis engine to be, you may decide to add more “weight” to something written in upper case as it expresses a bit more enthusiasm. In the past, I’ve generally changed all incoming text to uppercase but haven’t introduced additional scoring so this can be optional. That said, it’s could to get your data in a standard format.
- Tokenisation – this is simply the process of splitting your cleansed sentence into a collection of tokens (or words) – like this:

Having the information in this format makes it easier to process and manipulate.
- Stop Words – in computing terms, these are words that are filtered out of the text that you’re processing. Unfortunately, there isn’t a definitive list of stop words. Sometimes they are also known as “noise words”. One thing that can be said about stop words is they don’t often express much in the way of emotion, so it doesn’t make much sense to process them – again, this saves you processing time. Some examples of stop words can include words like – “a,able,about,across,after,all,almost,also,am,among”
After you’ve successfully obtained and cleansed your data, the next step is to create a Bayesian Classifier.
Naïve Bayesian Classifier
Performing sentiment analysis using Bayesian Theorem involves creating a Naïve Bayesian Classifier. This type of classifier is based on the Bayes Rule that we mentioned earlier. The classifier gets its name because of the initial assumptions that are made which may not be correct.
That said, with enough quality training data, it’s possible to make predictions with a Bayesian Classifier that hit the 70%-80% accuracy mark!
nBayes
You can either write one from scratch using the formula we’ve been looking at, alternatively, there is a great one on GitHub based on Paul Grahams spam filter which is called nBayes. It’s a good classifier to get started with and it’s the one we’ll use.
Before dipping into the nBayes classifier, it’s worth mentioning some of the key classes that are used:
Index – this contains your training data. Entries are compared against each Index to check to see if they belong to said Index. Sentiment analysis will have a positive index and a negative index. – so, 2 in total.
Entry – This is a string that represents a “document” which you are trying to classify. This could be a Tweet.
Analyzer – This takes a new Entry and 2 Indexes and determines whether the Entry belongs to one Index or another.
For reference, I’ve taken a Fork of the GitHub repo which you can find it here.
Testing the Classifier
To test nBayes, we need to load each Index with examples of our training data then send some text into classify.
Loading the training data
In this code extract, you can see an example of training data being manually supplied to each Index:
Index positive = Index.CreateMemoryIndex();
Index negative = Index.CreateMemoryIndex();
// train the indexes
positive.Add(Entry.FromString("this is awesome?"));
positive.Add(Entry.FromString("i really enjoyed this program"));
positive.Add(Entry.FromString("the new event was GREAT!"));
positive.Add(Entry.FromString("I thought that new phone was ideal, the key features blew my mind!"));
positive.Add(Entry.FromString("OK, that's a super idea, lets do it!"));
negative.Add(Entry.FromString("That was terrible! What were you thinking?"));
negative.Add(Entry.FromString("OMG! No way! I can't believe that! Terrible!"));
negative.Add(Entry.FromString("I just got this new phone but wish I hadn't. It's pretty crap!"));
negative.Add(Entry.FromString("There's no way I'd sign up with them. Their service is terrible!"));
negative.Add(Entry.FromString("That's just rubbish!!!"));In the real world you’d generally have this stored somewhere like a database that can be easily accessed.
Invoking the Classifier
Next, we create an instance of the Analyzer class, passing in the string we want to categorise, along with our training data from both indices:
Analyzer analyzer = new Analyzer();
CategorizationResult result = analyzer.Categorize(Entry.FromString(input), positiveSentiment, negativeSentiment);Finally, we evaluate the result we get back from the nBayes classifier in the following switch statement:
switch (result)
{
case CategorizationResult.First:
Console.WriteLine("Positive sentiment");
break;
case CategorizationResult.Second:
Console.WriteLine("Negative sentiment");
break;
case CategorizationResult.Undetermined:
Console.WriteLine("Undecided");
break;
}
I’ve wrapped the above code we’ve just looked at into a method called TestClassifier. This accepts a string parameter called input. It gets invoked from a console application which you can see here:
static void Main(string[] args) { TestClassifier("i just read a new book by Seth Godin called Tribes.Awesome read. I recommend it!"); }
The Result!
So, we’ve set up nBayes with some training data and supplied a test value. How does it perform?
In this screenshot you can the result we get back from nBayes after passing in our string:
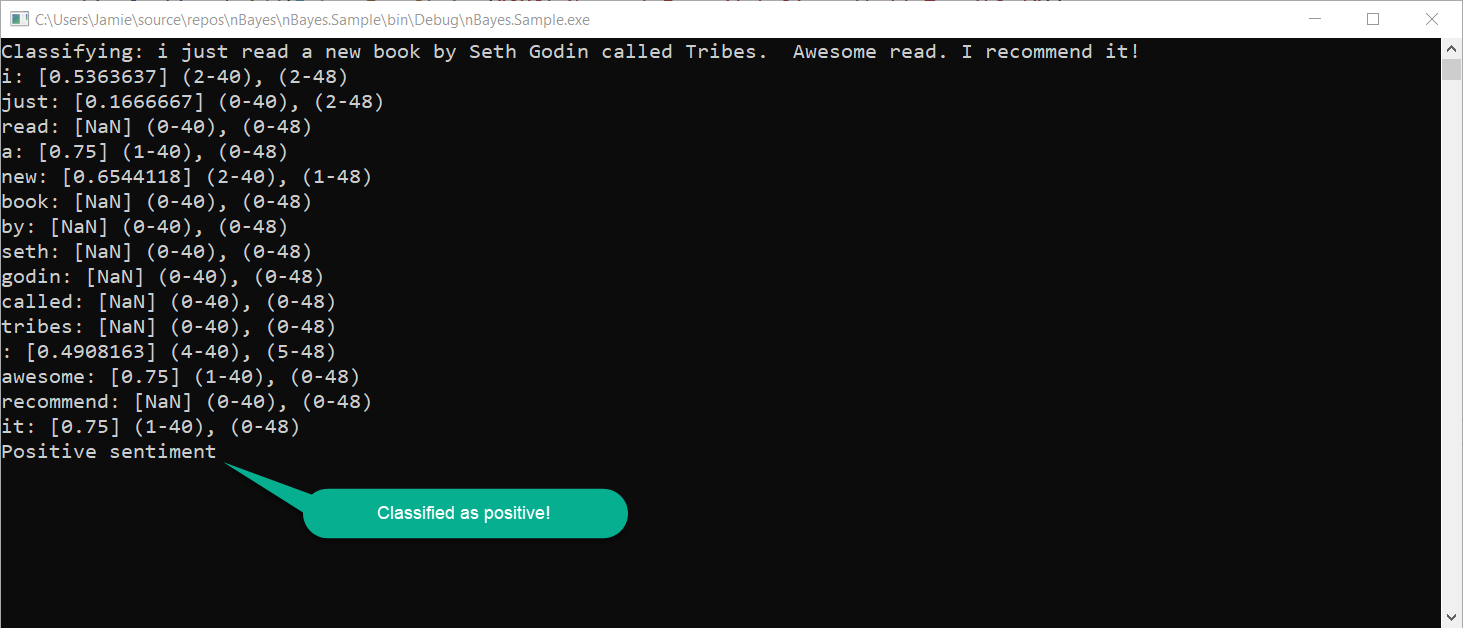
Here you can see that our classifier has correctly identified our string as expressing positive sentiment!
A closer look under the hood in the debugger, and we can see the probability being calculated for our string in relation to the category it belongs to (positive or negative):
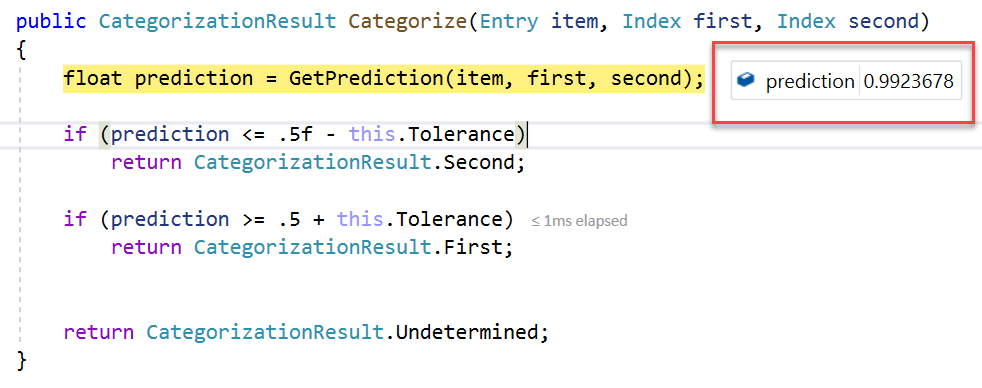
A recap:
- the parameter item contains the text we want to classify
- the parameter first contains our positive training data
- the parameter second contains our negative training data
- the closer to the value 1, the higher the degree of probability (or confidence)
In the above, you can see our text has been classified with 0.99 probability of belonging to the “first” index, i.e. the positive category.
Perfect!
Use cases
We’ve just looked at how you can leverage text classification techniques to perform sentiment analysis. There are many use cases for this technology, some include but are not limited to:
Opinion mining – identify how your product, brand or service is being perceived online. Integrate with Facebook, Twitter or Instagram APIs to surface valuable insights. Surface this information in web services or applications with rich visualisations, thereby giving you a 360-degree view!
Corporate email – use text classification and sentiment analysis to get a feel for the current tonality of your corporate email. Use this data to triage potentially difficult or contentious topics.
Chatbots – Are you creating chatbots? Use sentiment analysis to identify if a user is expressing negative emotion or frustration. Hand over the conversation to a human agent at this point thereby improving the user experience!
These are just some use cases that sentiment analysis and text analytics can be applied to and I’m sure you have ideas of your own!
Summary
In this blog post we’ve introduced Bayesian Theorem. We’ve seen how the Bayes Rule can be leveraged to perform sentiment analysis and looked at an open-source implementation of the rule called nBayes.
We ran through an example of the code in action and saw how we were able to successfully classify incoming text into the correct category.
Are you considering implementing text classification, NLP or sentiment analysis in your products or services?

Jamie Maguire is a Microsoft MVP, software architect, and a community leader in his roles at Code Club and STEM Learning UK. He has 20 years of software development experience, which goes back to the very first version of the . NET framework.
Resgistrate para recibir consejos sobre Microsoft Azure y Dynamics
- Puestos de trabajo como desarrollador de Nube inteligente
- Puestos de trabajo como consultor técnico de Nube inteligente
- Puestos de trabajo como consultor funcional de Nube inteligente
- Puestos de trabajo como gestor de proyectos de Nube inteligente
- Puestos de trabajo como arquitecto de soluciones de Nube inteligente
- Puestos de trabajo como analista comercial de Nube inteligente
- Puestos de trabajo como arquitecto técnico de Nube inteligente
- Puestos de trabajo como Administrador de sistemas de Nube inteligente
- Puestos de trabajo de ventas para Nube inteligente
- Otros puestos de trabajo para Nube inteligente
- Puestos de trabajo como desarrollador de Lugar de trabajo moderno
- Puestos de trabajo como consultor técnico de Lugar de trabajo moderno
- Puestos de trabajo como consultor funcional de Lugar de trabajo moderno
- Puestos de trabajo como gestor de proyectos de Lugar de trabajo moderno
- Puestos de trabajo comoAdministrador de sistemas de Lugar de trabajo moderno
- Puestos de trabajo como arquitecto de soluciones de Lugar de trabajo moderno
- Otros puestos de trabajo para Lugar de trabajo moderno
- Puestos de trabajo como desarrollador de Aplicaciones empresariales
- Puestos de trabajo como consultor técnico de Aplicaciones empresariales
- Puestos de trabajo como consultor funcional de Aplicaciones empresariales
- Puestos de trabajo como gestor de proyectos de Aplicaciones empresariales
- Puestos de trabajo como analista comercial de Aplicaciones empresariales
- Puestos de trabajo como Administrador de sistemas de Aplicaciones empresariales
- Puestos de trabajo como arquitecto técnico de Aplicaciones empresariales
- Puestos de trabajo como arquitecto de soluciones de Aplicaciones empresariales
- Puestos de trabajo de ventas para Aplicaciones empresariales
- Puestos de trabajo como gerente de TI de Aplicaciones empresariales
- Otros puestos de trabajo para Aplicaciones empresariales